Does Re-ranking Improve the Performance of RAG?
Yes, re-ranking is a crucial step that can significantly improve the performance of a Retrieval-Augmented Generation (RAG) system. While the initial retrieval stage fetches a broad set of documents, the re-ranking stage refines this set, ensuring that only the most relevant and highest-quality information is passed to the LLM.
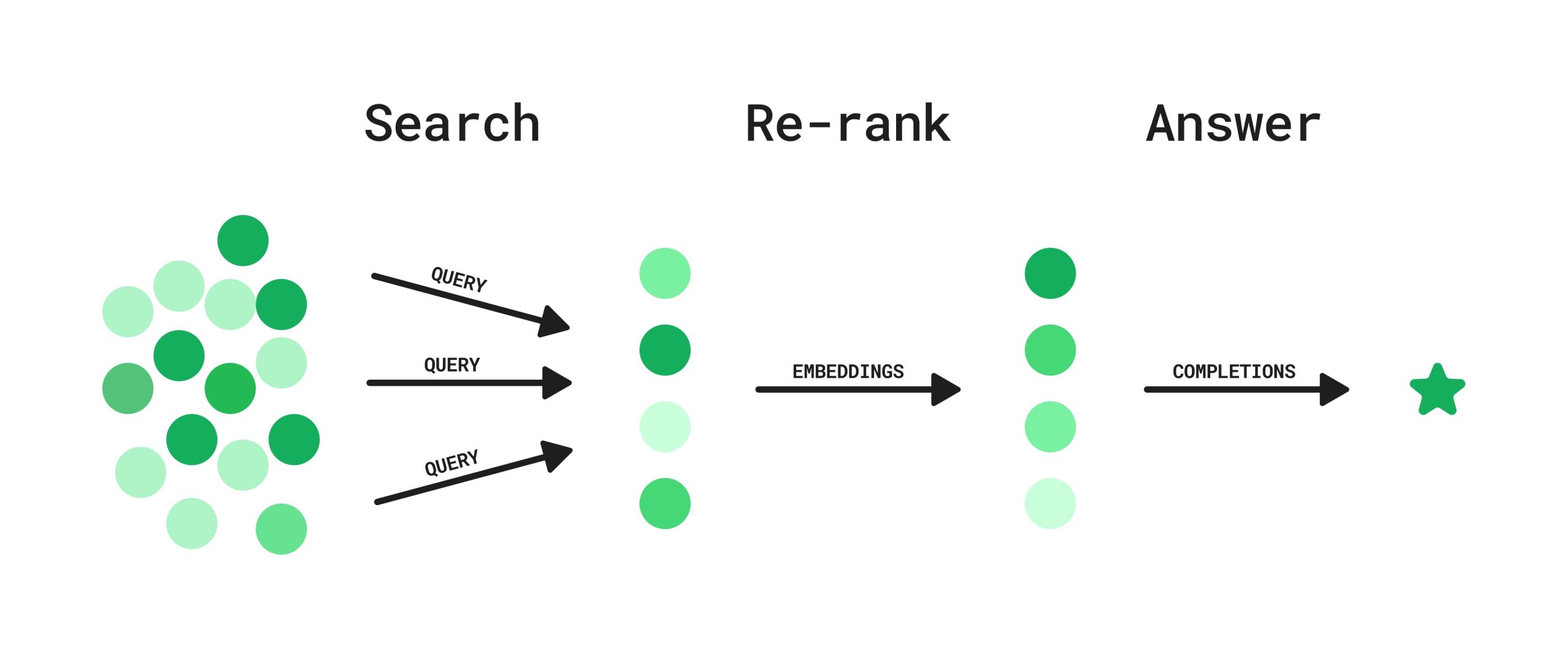
Let's look at the process in more detail.
1. Classical RAG
In a traditional RAG pipeline, the process is as follows:
- Retriever: A dense retriever (e.g., FAISS, DPR) or a sparse retriever (e.g., BM25) fetches the top-k passages.
- Generator: An LLM (like GPT-4) conditions its response on these k passages to produce an answer.
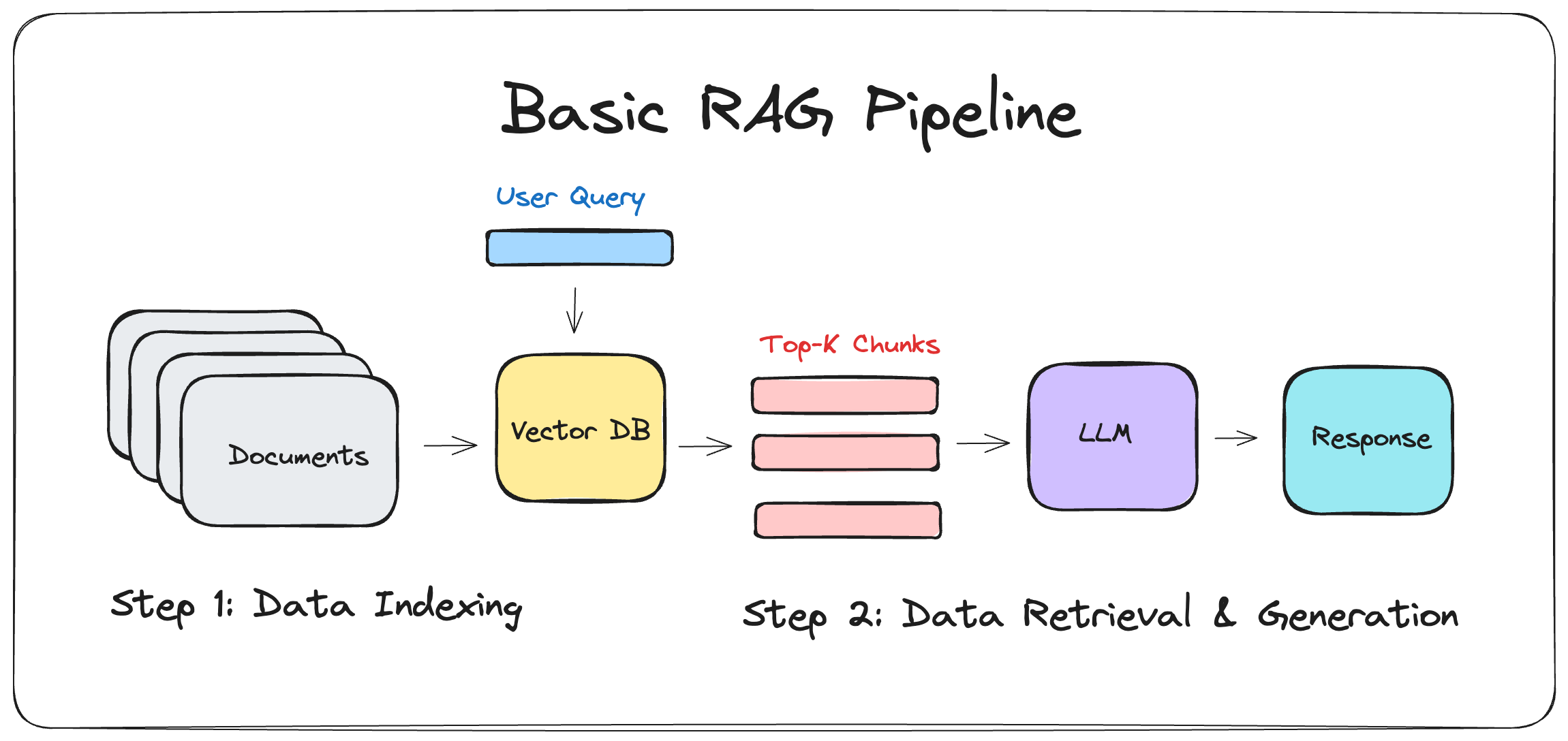
Problem:
- Increase token input length, leading to higher cost.
- Make the LLM’s reasoning harder, potentially causing hallucinations or irrelevant content.
2. With Re-ranking Models
Re-ranking is a fine-grained retrieval step that analyzes the relationship between a query and documents more deeply. After the initial retrieval, the top document chunks are passed through a re-ranking model, which re-sorts them in descending order based on their importance to the input query.
Types of Re-ranking Models:
- Cross-Encoder based models: ColBERT, ColBERTv2
- LLM-based re-ranking models: RankGPT
- API-based models: CohereAPI
Cross-Encoder based Models: ColBERT
ColBERT uses a basic BERT model to encode tokens into embeddings, which is a good choice because:
- Masked Language Modeling (BERT): ColBERT leverages BERT's Masked Language Modeling, predicting randomly masked tokens with a bidirectional approach (seeing both past and future tokens), resulting in strong contextualized embeddings.
- Causal Modeling (LLM): In contrast, Causal Modeling predicts the next token in a sequence and is unidirectional. While ideal for generation, the bidirectional embeddings from BERT are more effective for retrieval tasks.
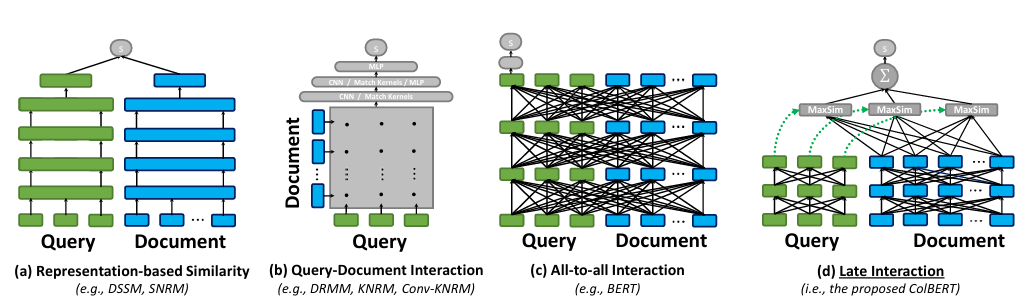
The core concept behind ColBERT is late interaction. Unlike other models that create a single embedding for a document, ColBERT creates an embedding for every token in the query and every token in the document using a pre-trained BERT-based encoder.
During the re-ranking process, ColBERT calculates a similarity score for every token in the query against all tokens in the documents. It then takes the maximum similarity score for each query token and sums them to determine the document's final relevance score.
The retrieval process in ColBERT is split into two stages:
Approximate Filtering: For each query embedding, a separate vector similarity search is performed on the FAISS index. The search finds the top-k' most similar document embeddings from the entire collection. The IVFPQ index speeds up this search by searching only a few nearest partitions (p nearest cells). The results of these Nq searches (one for each query embedding) are combined, and the unique document IDs are collected into a set of K candidate documents. These K documents are likely to contain embeddings highly similar to the query embeddings.
Re-ranking and Refinement: Once the smaller set of K candidate documents is identified, a precise re-ranking finds the final top-k results. The full ColBERT scoring process (MaxSim) is applied to these K documents. The relevance score for each candidate is calculated by summing the maximum similarity between each query embedding and all document embeddings. The documents are then sorted by score, and the top-k are returned as the final result.
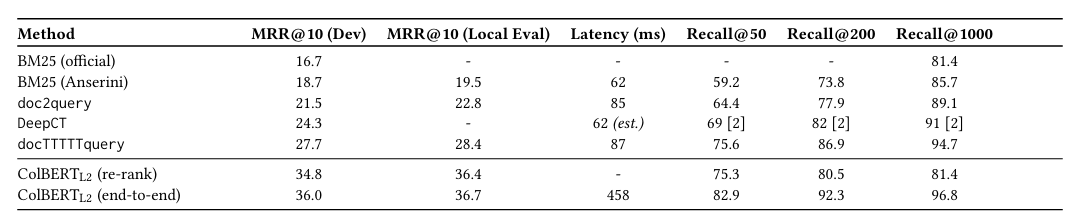
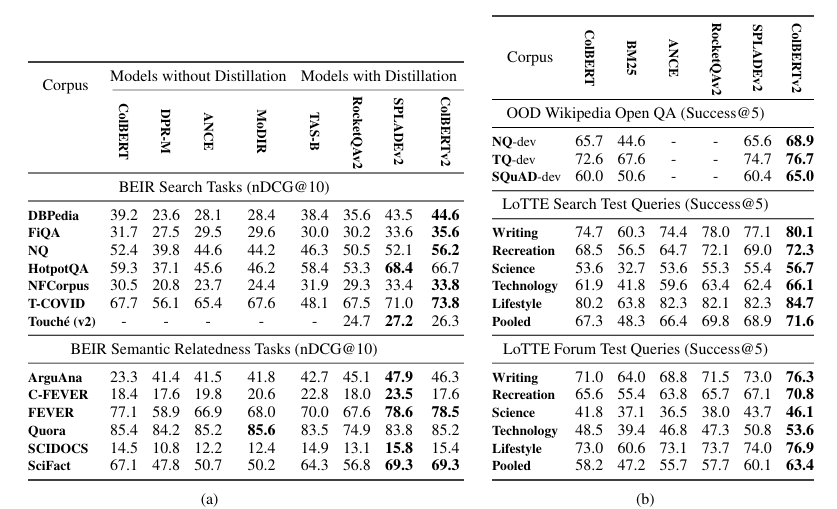
ColBERTv2
ColBERTv2 is an improvement over ColBERT on two key features: the training strategy and compressed indexing. An initial ColBERT model is used to index the training passages. For each training query, this model retrieves the top-k passages, which often include a mix of relevant documents and challenging, but irrelevant, documents (hard negatives) that are semantically similar to the query.
1. Knowledge Distillation
For training, knowledge distillation of a powerful cross-encoder model like ms-macro-MiniLM-L-6-V2 is used as a teacher model. The scores from the cross-encoder are used to train the ColBERT student model. ColBERTv2 uses a KL-Divergence loss to distill the teacher's scores into its architecture, helping the student model mimic the teacher's ranking distribution. To further improve training, the process also uses in-batch negatives, where a cross-entropy loss is applied to the positive score of each query against all passages corresponding to other queries in the same batch.
2. Indexing
MaxSim is applied on a reduced inverted list in a two-stage retrieval process to improve efficiency. This two-step process allows for fast candidate generation using approximate scores, followed by a more accurate re-ranking of the top passages.
Candidate Generation with the Reduced Inverted List
This first stage is for speed and efficiency. The goal is to quickly identify a small set of promising documents without decompressing all the vectors.
- Query Encoding: The query is encoded into a set of multi-vector representations, one for each token.
- Centroid Lookup: For each query token vector, the system finds its nearest nprobe centroids. nprobe is a hyperparameter that controls how many clusters to search.
- Inverted List Traversal: Using these centroid IDs, the system accesses the inverted list. This list maps each centroid to the compressed passage embeddings that are closest to it.
- Approximate MaxSim: For each query vector, an approximate "MaxSim" operation is conducted. This involves calculating the similarity between the query vector and the decompressed passage embeddings from the inverted list. This computes a lower-bound on the true MaxSim score, which is a good proxy for relevance.
- Candidate Selection: The lower-bound scores are summed across the query's tokens to get an overall score for each passage. The top ncandidate passages with the highest approximate scores are selected for the next stage.
Decompression and Full MaxSim Calculation
For each of the ncandidate passages, the system loads and fully decompresses all of its token embeddings by combining the centroid and the residual vector. The true MaxSim operation is then performed. This involves calculating the cosine similarity between each query token vector and all of the uncompressed passage token vectors, and then summing up the maximum similarities.
LLM-based Re-ranking Models: RankGPT
RankGPT uses permutation knowledge distillation instead of traditional supervised fine-tuning. The approach has two main components: sliding window data generation and permutation distillation with RankNet loss.
Sliding Window:
Given a query q and a candidate set of passages $\mathcal{P} = \{p_1, p_2, \dots, p_M\}$, the teacher LLM produces a high-quality ranked list:
$$R = \{r_1, r_2, \dots, r_M\}, \quad r_i = \text{rank}(p_i)$$
Since LLMs cannot process all $M$ passages at once, passages are split into overlapping windows of size $w$:
$$\mathcal{W}_k = \{p_k, p_{k+1}, \dots, p_{k+w-1}\}, \quad k=1, \dots, M-w+1$$
The teacher re-ranks passages inside each window. At step $k$, the relative order of the top-$t$ passages is locked in while the window slides backward through the list.
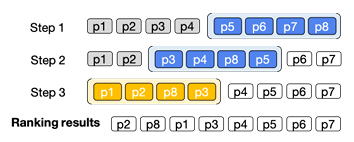
Permutation Distillation:
The student model $f_\theta(q, p_i) = s_i$ assigns a score $s_i$ to each passage $p_i$. Instead of absolute scores, RankNet uses pairwise ordering:
$$L_{\text{RankNet}} = \sum_{i=1}^{M}\sum_{j=1}^{M} \mathbf{1}_{r_i < r_j} \, \log\!\big(1 + \exp(s_j - s_i)\big)$$
Where:
- $M$: number of passages
- $r_i$: rank of passage $p_i$ from teacher
- $s_i$: predicted score from student
- $\mathbf{1}_{r_i < r_j}$: indicator if passage $p_i$ is more relevant than $p_j$
Intuitively:
- If $r_i < r_j$ (i.e., $p_i$ is more relevant), we want $s_i > s_j$.
- If the student gets it wrong ($s_j > s_i$), then $(s_j - s_i) > 0$ and the loss increases.
- If it gets it right ($s_i > s_j$), then $(s_j - s_i) < 0$ and the loss approaches $0$.
Thus, the student (e.g., a BERT cross-encoder) learns to approximate the teacher’s ranking by minimizing pairwise inversions rather than predicting exact permutations.
References
- Khattab, O., & Zaharia, M. (2020). ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. SIGIR.
- Santhanam, K., et al. (2022). ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction. arXiv:2112.01488.
- Sun, S., et al. (2023). RankGPT: Instruction Tuning for Generative Ranking. arXiv:2304.09569.
- Cohere AI. (2023). Cohere Rerank API Documentation. Retrieved from https://docs.cohere.com.