Retrieval-Augmented Generation (RAG) System for Academic Research Papers
In the naive RAG, we saw different sections of RAG like indexing, retrieval and generation. However, this is not the end of the world—we can see how these basic modules in the naive RAG can be tweaked to cater to a real-world application that is more robust.
Overview
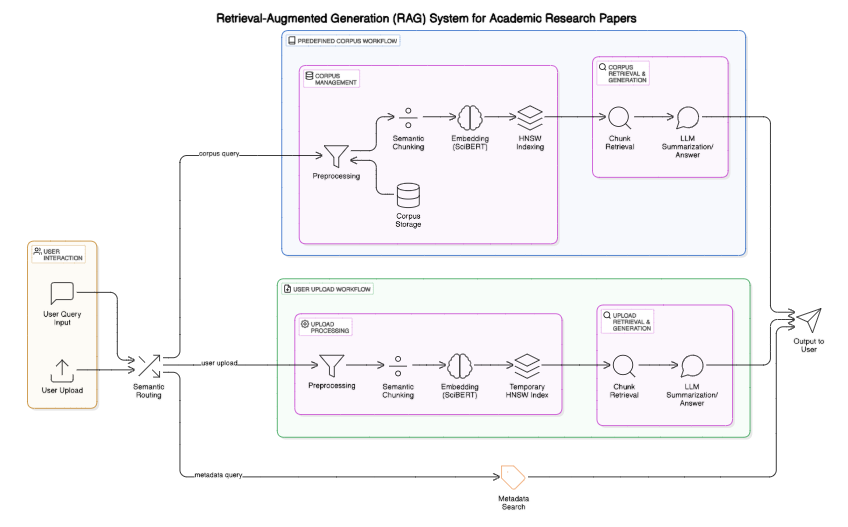
Research papers are often written with a single audience in mind, but real-world readers have different goals and backgrounds. In this work, we develop a system that generates role-aware summaries, adapting the tone and content of a paper’s summary to suit the reader’s perspective. Our approach identifies the intent behind a user’s query and routes it to a summarization strategy that balances factual accuracy with contextual relevance. The system is designed to be modular such that it can process user queries through one of three distinct pathways: corpus-level summarization, document-specific summarization, and metadata extraction.
Each route has a similar basic pipeline (preprocessing, semantic indexing, and response generation), but operates on different data sources and task scopes. Figure 1 provides a high-level overview of our end-to-end pipeline, which we describe in detail in the rest of this section.
At its core, our system combines dense vector retrieval with generative language modeling. When given a query \( q \) and a corpus of documents or papers \( D \), it generates a summary \( y \) as follows:
\( y^* = \arg\max_y \; P(y \mid q, R(q, D); \theta) \quad \text{(1)} \)
Here, \( R(q, D) \) is the set of document chunks retrieved in response to the query \( q \), and \( \theta \) represents all the parameters of the generative language model used.
Dataset and Knowledge Base
To support flexible and accurate query answering, the system combines a large-scale academic corpus with dynamic user inputs. For the background knowledge base, the entire arXiv Dataset for Summarization from Hugging Face [1] sounds to be a good choice, which contains thousands of arXiv papers paired with their abstracts. This corpus spans a wide range of scientific fields, providing the system with a strong foundation of factual, domain-specific knowledge.
In addition to this static corpus, users can also upload any number of their own PDF documents—whether they’re unpublished papers, project reports, or drafts. Once uploaded, the system automatically processes these documents and builds a custom vector database on the fly. This enables fast semantic retrieval across both public and user-specific content, ensuring that responses are grounded in the most relevant and personalized information available.
Semantic Routing
Semantic Routing is necessary because, based on the query type provided, it is essential to route the query to the correct module. A key limitation in the initial system was its tendency to treat all queries the same. Regardless of user intent, the pipeline followed a uniform path, often producing mismatched, incoherent, or irrelevant summaries. To address this, a semantic routing layer was introduced that recognizes the type of question being asked and dynamically routes it to the most appropriate processing module.
The current implementation supports three distinct routing paths:
- Corpus Query Routing: These are broad, open-ended queries (e.g., "What are recent trends in transformer-based vision models?") that require synthesis across multiple papers. For such queries, a multi-document RAG pipeline is applied that retrieves relevant chunks from the entire corpus and generates a role-conditioned summary using a large language model. This route excels at cross-document exploration and thematic synthesis.
- Document-Specific Query Routing: When queries reference specific uploaded documents (e.g., "Summarize the results section of paper 3 for a policymaker"), retrieval scope is restricted to those documents. This approach improves factual alignment and reduces hallucinations by providing the LLM with a focused context window tailored to the user's intent.
- Metadata Query Routing: These are targeted queries about bibliographic or structural information from specific papers (e.g., "Who are the authors of NeRF: 'Representing Scenes as Neural Radiance Fields for View Synthesis'?"). A metadata module handles these queries through section-aware PDF parsing and rule-based heuristics to extract fields like title, authors, venue, and publication year. The parsed metadata is stored in a structured index for quick access.
Routing decisions employ a hybrid strategy that combines heuristic intent detection with semantic similarity scoring. Given a query embedding \( z_q \) and a set of prototype intent vectors \( \{z_c\}_{c \in C} \), the selected route \( c^* \) is defined as:
\( c^* = \arg\max_{c \in C} \cos(z_q, z_c) \)
where \( c^* \) is the set of routing classes and \( \cos(\cdot, \cdot) \) denotes cosine similarity. This lightweight formulation enables the system to handle diverse queries while maintaining interpretability and modularity.
Corpus- and Document-level Modules
Document Pre-processing and Semantic Chunking
Using the notations from Equation 1, let \( D = \{d_1, d_2, ..., d_N\} \) be a corpus of \( N \) documents or research papers. Each document \( d_i \) is split into sections, which are further divided into paragraphs. Most papers in \( D \) contain standard sections like abstract, introduction, methodology, results, and conclusion. These sections vary in their format and content—for example, methods and results typically contain more numerical and mathematical content than the introduction and conclusion.
Each document is segmented into text chunks \( x_{ij} \):
\( d_i \rightarrow \{x_{i1}, x_{i2}, ..., x_{iT} \} \)
Each \( x_{ij} \) represents an overlapping chunk of text (usually a paragraph or logical subsection) extracted from document \( d_i \), designed to capture a self-contained scientific argument, result, or claim. The following chunking constraints are applied:
- Chunks align with sentence boundaries where possible, using natural language parsing tools.
- Chunks maintain a 10% overlap as a buffer to ensure coherence and self-containment.
- The token length of each chunk is limited by a maximum threshold \( T_{\text{max}} \), where \( \text{len}(x_{ij}) \leq T_{\text{max}} \). In this implementation, \( T_{\text{max}} \) is set to 1000 tokens.
Dense Embedding and Retrieval Module
After segmentation, each chunk \( x \in D \) is converted into a dense vector using a sentence-level transformer model. SciBERT (a BERT-based model trained specifically on scientific text) [2] is used to capture technical language and domain-specific concepts common in research papers. SciBERT outperforms general-purpose models on this scientific content.
The embedding function \( f_{\phi} \), where \( \phi \) represents the SciBERT encoder parameters, is defined such that for any text chunk \( x \) and user query \( q \), the vector representations are:
\( z_x = f_{\phi}(x), \quad z_q = f_{\phi}(q) \)
Since both vectors exist in the same semantic space, similarity is measured using cosine distance. The most relevant content is retrieved by selecting the top-\( k \) chunks based on this similarity:
\( R(q, D) = \text{top-}k \{ x \in D : \cos(z_q, z_x) \} \quad \text{(2)} \)
\( \cos(a, b) = \frac{a \cdot b}{\|a\| \|b\|} \quad \text{(3)} \)
The HNSW (Hierarchical Navigable Small World) [3] indexing strategy from the FAISS (Facebook AI Similarity Search) library [4] is implemented to store and search all \( z_x \) vectors. Unlike the previous flat indexing approach using brute-force search across the entire embedding space, HNSW creates a multi-layer graph where nodes represent embeddings and edges connect semantically similar points. This structure enables more efficient approximate nearest neighbor (ANN) search, particularly when handling multiple documents.
After retrieving the top-\( k \) most relevant chunks, these are passed to the generation module, where they are combined with the user's query and prompt instructions to produce a role-aware response using a large language model (LLM).
Generative Language Modeling and Role-based Conditioning
After retrieving relevant context chunks using semantic similarity search, the next stage of the pipeline is language generation; this phase acts on the outputs of all three previous modules (corpus, metadata, and user-uploaded PDFs). A large language model (LLM) is used that has been conditioned on both retrieved evidence and user-specific instructions.
Using the set of top-\(k\) retrieved segments \( R(q, D) = \{x_1, x_2, \ldots, x_k\} \) from the previous step, a single, concatenated prompt \( c \) is generated, which acts as input to a generative transformer model. Currently, Google’s Gemini 2.0 Flash (for this project the LLM model was not fine-tuned, then Gemini made a good sense) is used, as it supports longer contexts, has proven zero-shot summarization capabilities, and follows instructions well—aligning with the goal of role-based conditioning.
The final decoding objective, as shown in Equation 1, is approximated by constructing a prompt c
from the retrieved chunks \( R(q, D) \) and decoding with a generative language model.
The model autoregressively generates the output sequence \( y = \{y_1, y_2, \ldots, y_T\} \) by maximizing its conditional log-likelihood:
\( P(y \mid c; \theta) = \prod_{t=1}^{T} P(y_t \mid y_{\lt t}, c; \theta) \)
where \( \theta \) are the model parameters, \( y_{\lt t} \) represents all the tokens generated up to time \( t \), and \( c \) includes both the retrieved context and any additional instructions or context we provide to facilitate role-based conditioning.
The context vector \( c \) is of the form:
c = [INSTRUCTION: "Summarize this paper..."] + [RETRIEVED_CONTEXT]This approach does not modify the underlying model weights; instead, it acts as a form of soft conditioning, similar to prefix- or prompt-tuning approaches used in parameter-efficient fine-tuning methods.
Applications
A variety of role-based prompt templates have been designed, allowing users to shape how information is presented in the final outcome. Some examples include:
- Corpus module: "Explain interpretable machine learning to a policymaker."
- PDF-based module: "Summarize this uploaded report for a product manager who needs to decide whether to deploy this system."
- Metadata module: "Provide a quick citation-style summary including the paper’s title, authors, venue, and year for a researcher updating their bibliography."
Acknowledgement
Special thanks to Avanti B. for diligently documenting everything during the project. Your notes were incredibly helpful as I worked on writing this documentation.
References
- Cohan, Arman, et al. “A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents.” NAACL HLT Short Papers (June 2018). Available at Hugging Face: ccdv/arxiv-summarization (accessed May 2025)
- Beltagy, Iz, Kyle Lo, and Arman Cohan. "SciBERT: A pretrained language model for scientific text." arXiv preprint arXiv:1903.10676 (2019).
- Malkov, Yu. A., and D. A. Yashunin. “Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs.” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 42, no. 4, Apr. 2020, pp. 824–36. IEEE.
- Johnson, Jeff, Matthijs Douze, and Hervé Jégou. “Billion-Scale Similarity Search with GPUs.” IEEE Transactions on Big Data, vol. 7, no. 3, July 2021, pp. 535–47. IEEE.